
This is a follow-up article to the report on the massive AWS cloud storage service outage that occurred earlier this week. The original report can be viewed here:
Massive AWS Cloud Outage May Frighten Enterprise Companies – Part 1
In the world of technology, things fail all the time, and outages are a part of the game. Just because you are on the cloud, it doesn’t mean that you are never going to face an outage. If that were the case, most of the cloud providers would have just a few really large data centers in each country rather than trying to build as many as they can.
This is not the first time Amazon Web Services is facing a serious outage. Two years ago, on September 20, 2015, several services from the US-EAST-1 region went down due to problems in their NoSQL database, DynamoDB. The details of the outage can be had from Amazon’s blog post here.
We still don’t know the root cause of the recent outage, but we do know that not many companies have learned the lessons of the past. Despite the incident, many decided to take a chance without actively working to cover all their bases and keep their services running in case of a major outage.
But there is one company that kept smiling during the last outage and is possibly smiling again during the recent outage. Because they actively worked out a plan, had a strategy and covered as much ground as possible to make sure that their service doesn’t go down that easily, even if the whole cloud region goes down.
Netflix did it before, and has now done it again. You can read Netflix’s Multi-Regional Resiliency plan here and see how carefully they keep breaking their own systems to make sure that are able to face every possible threat that can be thrown at them. It’s a must-read for every organisation that is already on the cloud; more importantly, it is also for the ones that are still sitting on the sidelines.
Let’s take a closer look at how Netflix planned for failure.
To make sure that their service hits their internal availability goal of 99.99% Netflix follows an Active-Active system, which is to essentially having multiple regions deployed at all times to serve their applications. They can work together when needed, or work all by themselves when required.
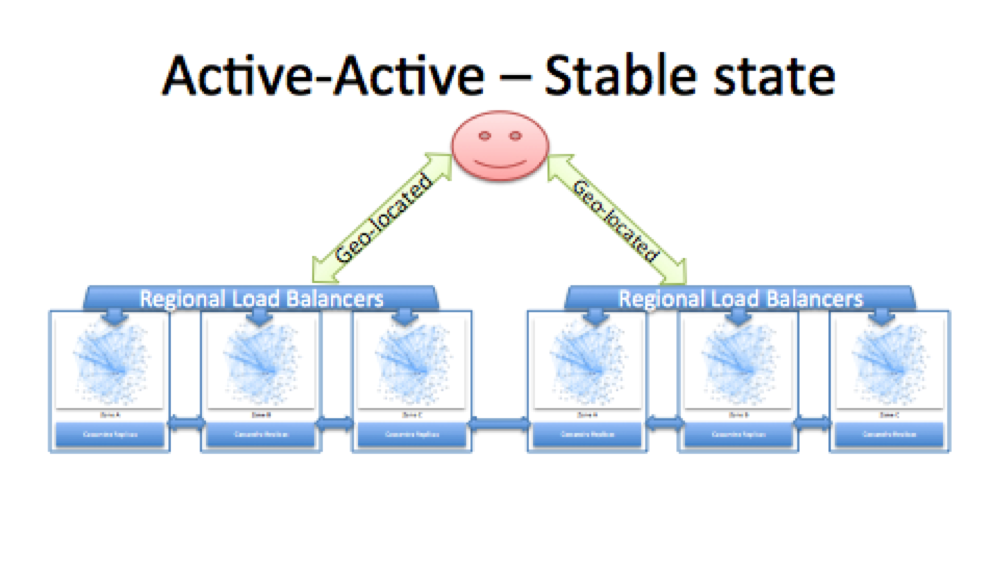
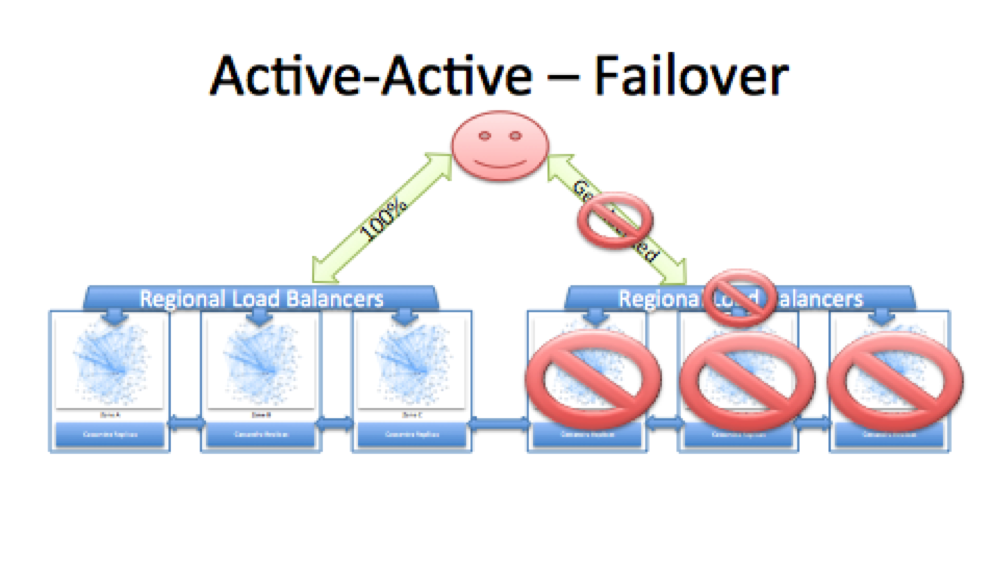
“In a normal state of operation, users would be geo-DNS routed to the closest AWS Region, with a rough split of 50/50%. In the event of any significant region-wide outage, we have tools to override geo-DNS and direct all of users traffic to a healthy Region.”
Netflix’s blog post goes into great detail about how they direct traffic to their services, and how they overcame the data replication headaches for an Active-Active solution. Netflix constantly keeps testing its architecture’s resiliency by breaking its own systems to verify that they are ready for any disruption, similar to how auto companies use crash tests to find faults and fix them.
That’s great for Netflix, but the point here is that with a little bit of planning and some extra effort, you can increase resiliency and availability even if you have single public cloud vendor.
Multi-cloud is another option that IT administrators should consider. It’s a bit more complex to execute but, if done properly, it will massively increase resiliency, while also making sure that you never have to worry about vendor lock-in. From that perspective, it’s actually better than the system Netflix uses.
Amazon’s AWS outage could not have come at a better time. The cloud industry is on a massive growth path, and it will be our collective responsibility to make some big mistakes and keep learning from them. The companies that saw their services go down for several hours yesterday are to be blamed. They had historical evidence that an outage was definitely possible, but the majority of them did not plan for it.
As such, this outage cannot be seen as a failure of the cloud model. In fact, a solution that includes cloud is often better than purely in-house infrastructure because of the resiliency it offers.
Thanks for reading our work! We invite you to check out our Essentials of Cloud Computing page, which covers the basics of cloud computing, its components, various deployment models, historical, current and forecast data for the cloud computing industry, and even a glossary of cloud computing terms.


