
Predictive analytics is an evolved component of data analytics that uses past data to arrive as possible future outcomes. It employs machine learning and statistical modeling of data to predict what will happen in a given scenario based on vast amounts of structured and unstructured data harvested over time.
In the business context, the term predictive analytics is sometimes wrongly interchanged with business intelligence, or BI. They are two distinct fields of study, the former dealing with future outcomes and the latter dealing with the current state of things. In simple terms, business intelligence or descriptive analytics is about gaining hindsight, while predictive analytics is about gaining insight and foresight.
How is Predictive Analytics Connected to Big Data?
Big Data refers to extremely large data sets that are beyond the capacity of traditional data modeling techniques can handle. It refers to both structured and unstructured data. Some examples of such large data sets are social media content, website indexing as conducted by search engines, fraud detection in the financial industry and threat detection in cyber security.
Predictive analytics is increasingly being engaged where Big Data resides, because it provides the foresight required to make critical business decisions on an ongoing basis. Other methods of data analytics are inadequate at best, specifically when working with such massive data sets.
3 Key Components of Predictive Analytics
Data: Data is necessarily the primary component of any predictive analytics project. It is the foundation on which any analytical model is built. Without key data, possible outcomes are impossible to predict. For this reason, it is not only important to capture the data, but store it securely and make it quickly accessible.
The data warehousing part is often outsourced to companies dedicated to this endeavor. It not only frees the client’s resources to work on the actual analytics, but also ensures a certain service level with respect to data availability and the implementation of standard security protocols like user authentication.
Statistics: Regression analysis is one of the most commonly used predictive analytics techniques. It involves the relationship between a known parameter and an unknown parameter.
Based on the behavior or trends observed in the known parameter, and factoring several other elements, the unknown parameter can be predicted to a high degree of accuracy. For example, studying rash driving trends will give us invaluable information about the number of potential road accidents.
Assumptions: The third component is assumptions. Because predicting the future is never 100% accurate, certain reasonable assumptions need to be made on which those predicted outcomes depend.
It is important to periodically revisit these assumptions to ensure their accuracy and validity. Remember the sub-prime mortgage crisis that crippled the financial world?
The wrong assumption there was that the people who had taken these mortgages wouldn’t default en-masse. All the predictive models at the time were based on this wrong assumption, and we all know what happened following that.
7 Stages of Predictive Analytics
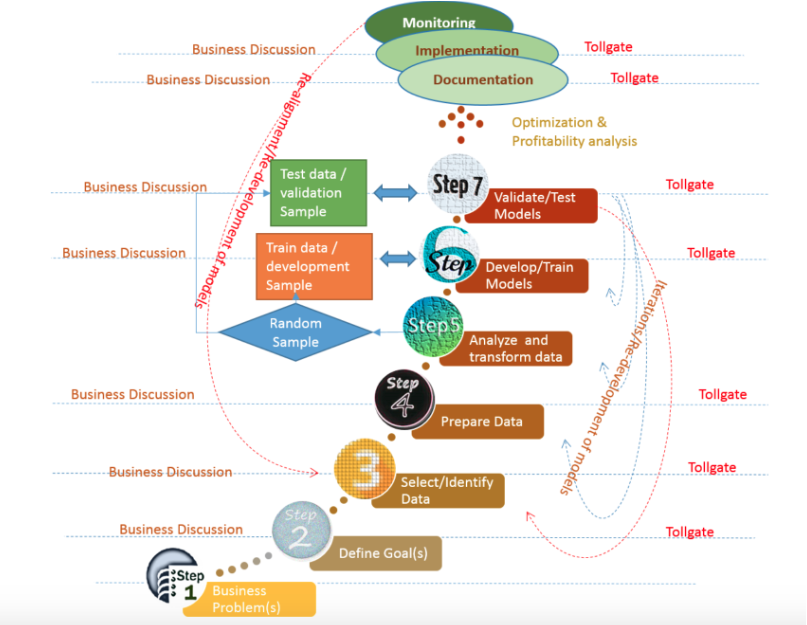
There are seven stages in the process of predictive analytics. Each stage has to be thoroughly executed in order for the entire process to produce results that are as close to real outcomes as possible.

Stage 1: Understand and Define Business Objective
Every predictive analytics project must necessarily begin with the end in mind. What are your goals? Is it to forecast revenue gains or losses; is it to reduce the number of fraudulent transactions? Is it to enhance customer satisfaction in a measurable manner? These goals will act as guidelines throughout the process.
Stage 2: Define Your Modeling Goals
This step involves translating your business goals into their analytics equivalents. For example, if you want to improve average customer spend over time, are you modeling for up-sell or cross-sell opportunities while tracking the average customer’s LTV (life time value)?
Stage 3: Selecting the Right Data
Any statistical model depends on the quality and accuracy of the underlying data in order to have a high degree of predictive value. This step requires choosing the most valuable data that can lead to the most accurate predictions. Such data can come directly from your customers, or acquired from third-party sources. Ensuring data accuracy, relevancy and validity is key to the success of your predictive analytics model.
Stage 4: Prepping your Data
The data used for modeling must be prepared for the analytical tools it will be used in. Machine learning can leverage unstructured data like never before by identifying patterns and trends, but the core data will still need to be in a structured format.
Stage 5: Variables Analysis and Transformation
Once the data has been given a certain format, the variables need to be transformed based on the type of modeling. The transformation can involve a number of approaches, including creating distinct groups and other types of treatment. The objective of this step is to bring normality into the variables so that they meet the assumptions of the statistical tests in the next stage.
Stage 6: Select, Develop and Train Models
This is the testing phase where the models are selected or developed/trained. Here are just a few examples of models that you can select individually or as a combination:

You then take the assumptions of the chosen algorithms and validate them, check for features like redundancies and multicolinearity of independent variables, develop and train the model on the training sample and finally check the performance of your model for accuracy, errors and so on.
Stage 7: Validate and Test Models
The final stage is to verify the stability of the model by doing cross-validation and other performance checks. It is also a good practice to score and predict using test samples. During this phase, you may have to go through multiple iterations after redeveloping your models.
Following the final stage is documentation, implementation and monitoring. In the last of these, you have to constantly realign your model by reviewing the core data to get more accurate results. It may also involve repeated iterations of your model.
Predictive Analytics is considered a very precise science even though it deals with a wide range of variables. However, keep in mind that accuracy is not the primary consideration. Factors like Base Rate, Specificity, Sensitivity, Precision and Recall are equally important, especially when trying to predict something like breast cancer in female patients.
The Accuracy Paradox states that a predictive model with a given rate of accuracy may actually have greater predictive power than a model with a higher rate of accuracy. For more on this, read this very interesting article on Towards Data Science by Tejumade Afonja.


